
字节跳动埋点数据流建设与治理实践
Flink拆分任务
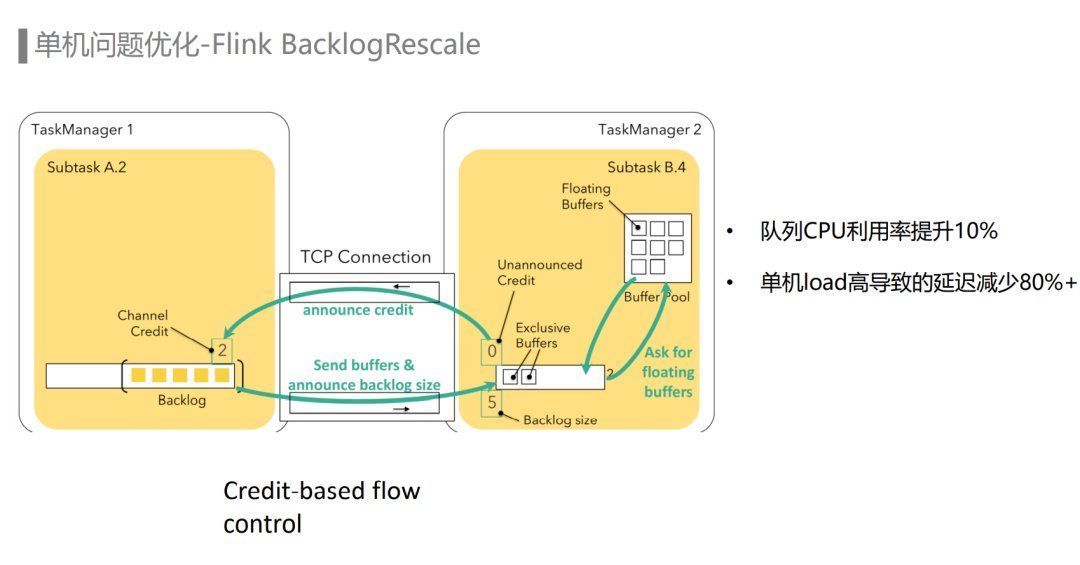
单机问题的类型有很多:队列负载不均、单机load高或者其他进程导致CPU负载高,以及一些硬件故障都可能导致Yarn单机问题。针对Yarn单机问题,我们从Flink和Yarn两个层面分别进行了优化,最终使单机load高导致的数据延迟减少了80%以上。
举个例子:一个客户端的文章点赞埋点,描述了一个用户在某一个时间点对某一篇文章进行了点赞操作,这个埋点经过埋点收集服务进入ETL链路,通过UserAction ETL处理后,实时地进入推荐Joiner任务中拼接生成样本,更新推荐模型,从而提升用户的使用体验。

那么在这么巨大的流量和任务规模下,埋点数据流主要处理的是哪些问题呢?我们来看几个具体的业务场景。
目前Flink能做到计算层面的流批一体,但计算和存储的流批一体还在探索阶段,接下来我们也会继续关注社区的进展。另外我们会尝试探索一些云原生的实时数据处理框架,尝试解决资源动态rescale的问题,以此来提升资源利用率。最后是在一些高优链路上,我们希望保障更高的SLA,比如端到端的exactly-once语义。
埋点数据流
埋点通过埋点收集服务接收到MQ,经过一系列的Flink实时ETL对埋点进行数据标准化、数据清洗、数据字段扩充、实时风控反作弊等处理,最终分发到不同的下游。下游主要包括推荐、广告、ABTest、行为分析系统、实时数仓、离线数仓等。因为埋点数据流处在整个数据处理链路的最上游,所以决定了“稳定性”是埋点数据流最为关注的一点。
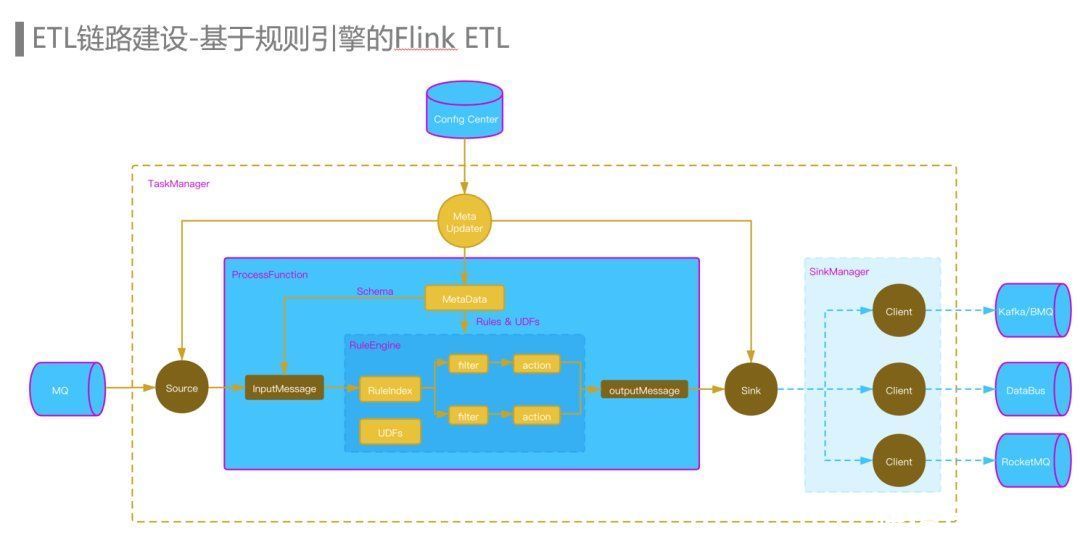
首先,我们在流量平台上配置了上下游数据集的拓扑关系、Schema和ETL规则,然后通过ConfigCenter将这些元数据发送给Flink ETL Job,每个Flink ETL Job的TaskManager都有一个Meta Updater更新线程,更新线程每分钟通过RPC请求从流量平台拉取并更新相关的元数据,Source operator从MQ Topic中消费到的数据传入ProcessFunction,根据MQ Topic对应的Schema信息反序列化为InputMessage,然后进入到规则引擎中,通过规则索引算法匹配出需要运行的规则,每条规则我们抽象为一个Filter模块和一个Action模块,Fliter和Action都支持UDF,Filter筛选命中后,会通过Action模块对数据进行字段的映射和清洗,然后输出到OutputMessage中,每条规则也指定了对应的下游数据集,路由信息也会一并写出。
埋点分级主要是针对离线存储成本进行优化,首先在流量平台上对埋点进行分级,埋点数据流ETL任务会将分级信息写入到埋点数据中。埋点数据在从MQ Dump到HDFS这个阶段根据这些分级的信息将埋点数据写入不同的HDFS分区路径下。然后通过不同的Spark任务消费不同分级分区的HDFS数据写入Hive Table。不同等级的分区可以优先保障高优埋点的产出,另外不同分区也可以配置不同的TTL,通过缩减低优数据的TTL节省了大量的存储资源。
第二个是对于Yarn节点上的DataNode把带宽打满或者CPU使用比较高影响节点上埋点数据流Flink任务稳定性的情况,通过给DataNode进行网络限速,CPU绑核等操作,避免了DataNode对Flink进程的影响。
服务端埋点

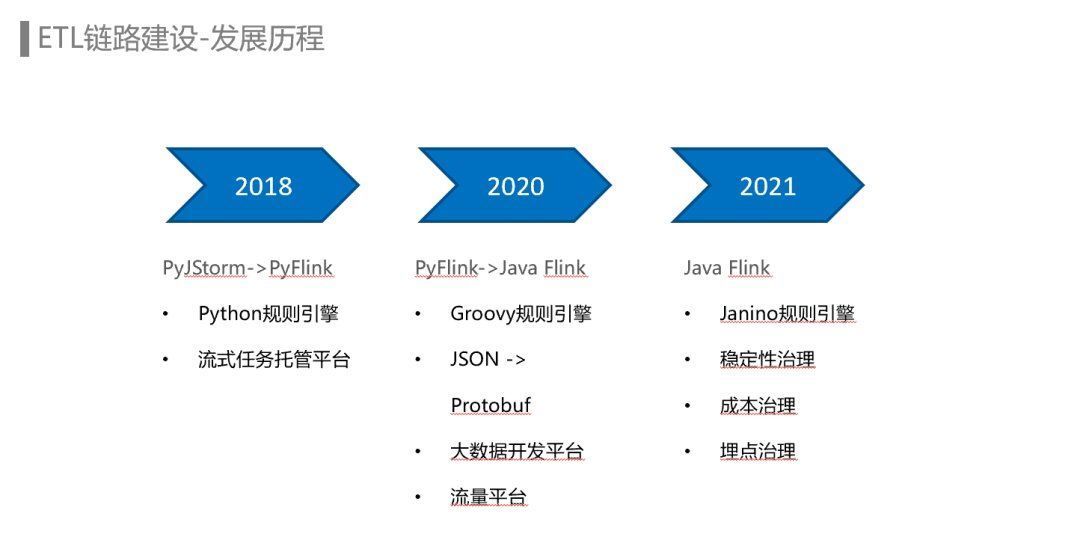
规则引擎为埋点数据流ETL链路提供了动态更新规则的能力,而埋点数据流Flink ETL Job使用的规则引擎也经历了从Python到Groovy再到Janino的迭代。
第三个是Yarn反调度的策略,目前字节跳动Flink使用的Yarn Gang Scheduler会按条件约束选择性地分配Yarn资源,在任务启动时均衡的放置Container,但是由于时间的推移,流量的变化等各种因素,队列还是会出现负载不均衡的情况,所以反调度策略就是为了解决这种负载不均衡而生的二次调度机制。
分流需求大多对SLA有一定要求,断流和数据延迟可能会影响下流的推荐效果、广告收入以及数据报表更新等。另外随着业务的发展,实时数据需求日益增加,分流规则新增和修改变得非常频繁,如果每次规则变动都需要修改代码和重启任务会对下游造成较大影响,因此在数据分流这个场景,规则的动态更新也是比较强的需求。
埋点数据流在字节跳动
字节跳动的埋点数据流规模
本文将介绍字节跳动在埋点数据流业务场景遇到的需求和挑战以及具体实践。
在埋点上报环节,通过在流量平台配置埋点的采样率对指定的埋点进行采样上报,在一些不需要统计全量埋点的场景能显著地降低埋点的上报量。